How LLMs Do Math and Why There’s a Better Way
We get asked a lot by investors, partners, friends, and family:
“Won’t the LLMs just figure this out?”
It’s a fair question. And since we started working on TrueMath, we’ve seen clear improvements in how language models handle math. They write better code, make fewer obvious mistakes, and in many cases, they sound more correct than ever. Or at least more confident.
But beneath that surface-level improvement lies the same core issue: language models don’t actually do math. They simulate the appearance of doing math. And the gap between sounding correct and being correct has real implications for anyone using AI in high-trust domains like finance, engineering, or compliance.
To explain why, let’s walk through what actually happens when LLMs do math.
Step 1: The model builds a strategy
This is the reasoning phase.
Let’s say you ask:
“What’s the monthly payment on a $500,000 house at 6 percent over 30 years?”
The model parses the prompt, recognizes the structure, and identifies the variables: loan amount, interest rate, and loan term. Then it selects a formula that seems appropriate based on its training data. Most likely, it lands on a version of the standard amortization formula.
At this point, nothing has been calculated. The model is performing pattern recognition, identifying the kind of problem being asked and a method for solving it. This is reasoning, not execution.
Step 2: The model writes and runs code (if allowed)
In tools like ChatGPT’s “Advanced Data Analysis” mode, the model will generate Python to perform the calculation. It might output something like:
import numpy as np
payment = np.pmt(0.06 / 12, 30 * 12, -500000)
Then it runs the code and returns the result.
“Your monthly payment would be $2,997.75.”
Sometimes that number is right. Sometimes it’s close. Sometimes it’s wrong. The model doesn’t know the difference.
And importantly, the model may or may not apply common sense or industry-standard assumptions. In this case, a $500,000 home is likely being financed with a 20% down payment. Ask the same question 10 times, and easily half the time the model will calculate the result using a $500,000 loan amount instead of $400,000. That’s not a rounding error. That’s the wrong problem.
This approach has hard limitations
It is based on language, not logic
LLMs are trained to predict text, not to guarantee correctness. They approximate answers by finding patterns in language, not by executing structured logic. When they select formulas, they’re choosing strings that resemble correct math. They’re not verifying anything.
It is non-deterministic
You can prompt the model with slightly different wording and get different results. Change the format, add a clarifying detail, or even just rephrase the same question, and the outcome may shift. There is no guarantee of consistency from one prompt to the next, or from one day to another.
It is not auditable
There’s no log of the assumptions used. No stored record of the logic. No versioning. No way to trace how a number was produced, or to prove that it would be the same tomorrow.
It is a blank slate every time
If you asked your LLM a mortgage question yesterday (or ten minutes ago), and ask again today, it starts from scratch. It rebuilds its logic from the ground up every time. That’s inefficient in both time and token cost. And more importantly, it’s brittle.
These are not bugs. They are architectural boundaries.
This is not about model quality. It’s not GPT-4 versus GPT-5 versus Gemini 3. Even the best models cannot solve this problem because they were not designed to. They don’t store logic. They don’t apply constraints. They don’t handle units. They don’t preserve assumptions over time. They don’t build prepared pathways that improve over repeated use.
You cannot prompt your way into determinism.
You cannot fine-tune your way into auditability.
You cannot scale your way into correctness.
So the question becomes: What kind of system should be doing the math in the first place?
A better approach separates roles
Here’s what a reliable system does:
- It uses LLMs to interpret the problem and extract structure.
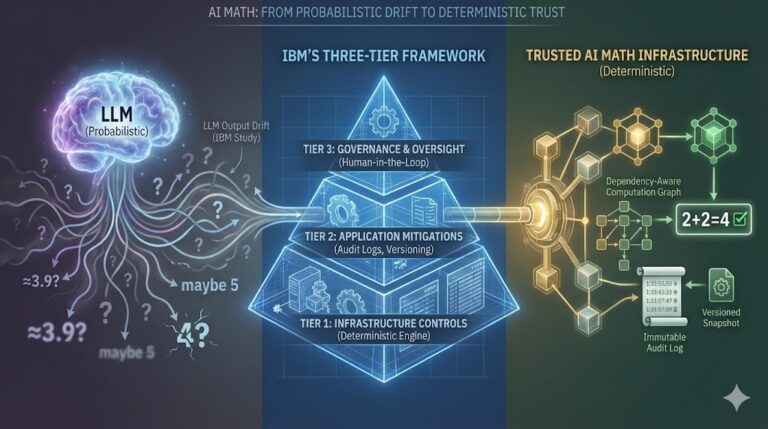
- It hands the structured input to a deterministic engine that performs the actual calculation.
- It stores inputs, assumptions, formulas, and results.
- It makes the math repeatable, explainable, and versioned.
This isn’t a wrapper. It isn’t a patch. It’s a system architecture based on separation of concerns. LLMs reason. Math engines execute. That boundary is not only useful. it is essential.
Why LLMs will never solve this on their own
Even with better tools, plugins, or integrations, language models are still performing statistical approximation. They were built to generate natural language, not structured execution. They will never store business logic, recall prior assumptions, resolve conflicting inputs, or validate correctness. Those are outside the scope of what language models are meant to do.
This is not a capability that will “emerge” with a larger or better-trained model. It is a structural limitation. Solving it requires a complementary system built for reliability, traceability, and math-first execution.
If you need a citation: IBM’s 2025 study led by Raffi Khatchadourian concluded that smaller models actually perform better for deterministic tasks, and that structured architectures must work alongside language models to produce reliable, repeatable results.
Final thought
There are plenty of cases where “close enough” is fine.
But if we want AI to move deeper into forecasting, underwriting, infrastructure planning, or anything involving large volumes of transactions, calculations, or compliance, this gap becomes a blocker.
The answer is not better prompts.
It is not more scale.
It is not a hope that the models will eventually figure it out.
The answer is to treat math as infrastructure.
That means separating reasoning from execution, and building each to do what it does best.
Reach out: bill.kelly@truemath.ai
Learn more: truemath.ai
Sign up for early access: https://app.truemath.ai/signup